Publications
2025
- L2M2: A Hierarchical Framework Integrating Large Language Model and Multi-agent Reinforcement LearningMinghong Geng, Shubham Pateria, Budhitama Subagdja, Lin Li, Xin Zhao, and Ah-Hwee TanIn Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25, Montreal, Canada, Aug 2025
Multi-agent reinforcement learning (MARL) has demonstrated remarkable success in collaborative tasks, yet faces significant challenges in scaling to complex scenarios requiring sustained planning and coordination across long horizons. While hierarchical approaches help decompose these tasks, they typically rely on hand-crafted subtasks and domainspecific knowledge, limiting their generalizability. We present L2M2, a novel hierarchical framework that leverages large language models (LLMs) for high-level strategic planning and MARL for lowlevel execution. L2M2 enables zero-shot planning that supports both end-to-end training and direct integration with pre-trained MARL models. Experiments in the VMAS environment demonstrate that L2M2’s LLM-guided MARL achieves superior performance while requiring less than 20% of the training samples compared to baseline methods. In the MOSMAC environment, L2M2 demonstrates strong performance with pre-defined subgoals and maintains substantial effectiveness without subgoals - scenarios where baseline methods consistently fail. Analysis through kernel density estimation reveals L2M2’s ability to automatically generate appropriate navigation plans, demonstrating its potential for addressing complex multi-agent coordination tasks.
@inproceedings{geng_l2m2_2025, location = {Montreal, Canada}, series = {IJCAI '25}, title = {L2M2: A Hierarchical Framework Integrating Large Language Model and Multi-agent Reinforcement Learning}, booktitle = {Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, {IJCAI-25}}, publisher = {International Joint Conferences on Artificial Intelligence Organization}, pages = {99--107}, author = {Geng, Minghong and Pateria, Shubham and Subagdja, Budhitama and Li, Lin and Zhao, Xin and Tan, Ah-Hwee}, month = aug, year = {2025}, doi = {10.24963/ijcai.2025/12}, url = {https://doi.org/10.24963/ijcai.2025/12}, dimensions = {false}, } - Hierarchical Frameworks for Scaling-up Multi-agent CoordinationMinghong GengIn Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, Detroit, MI, USA, May 2025
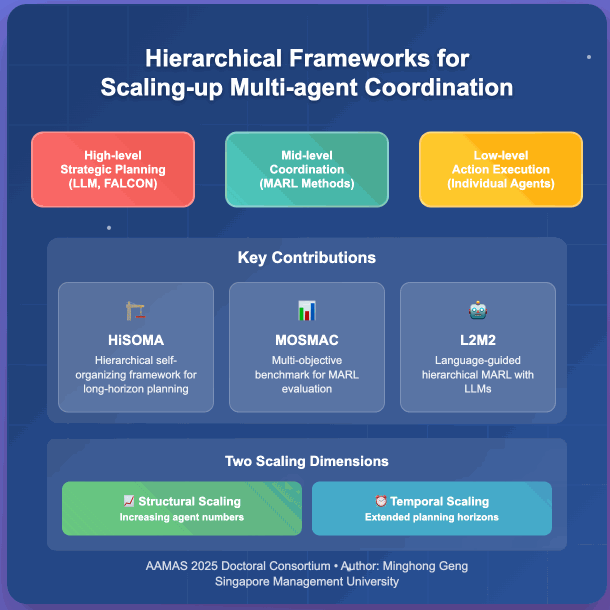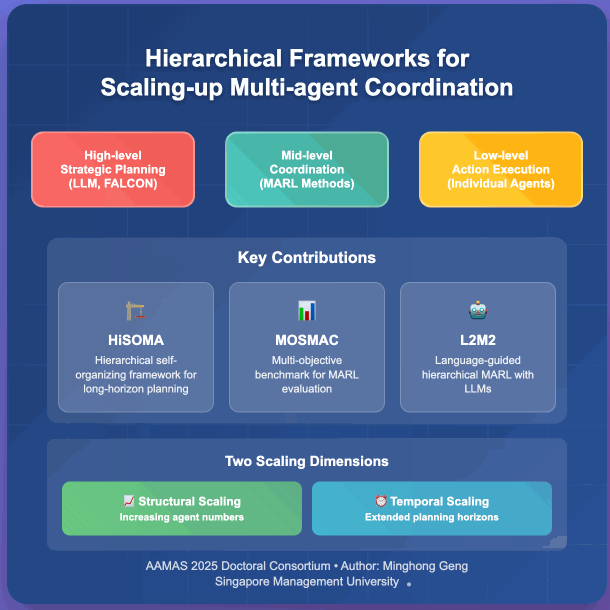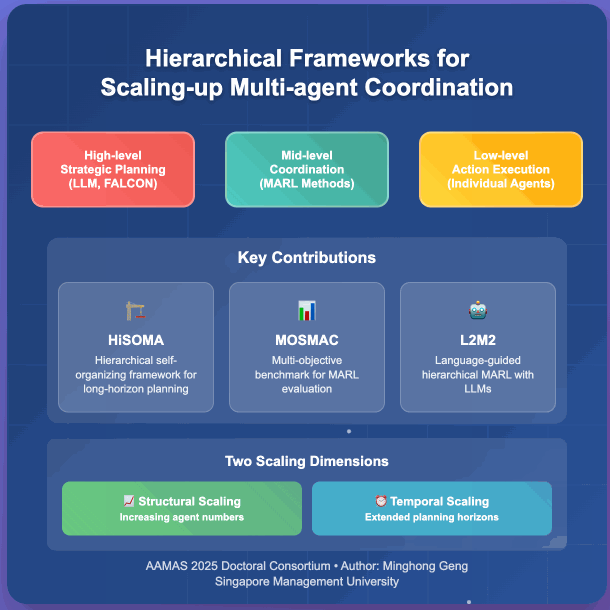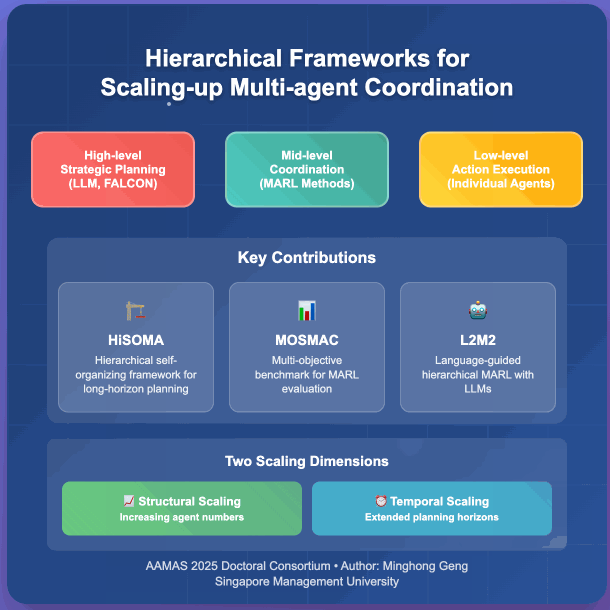
Multi-agent reinforcement learning has emerged as a powerful framework for developing collaborative behaviors in autonomous systems. However, existing MARL methods often struggle with scalability in terms of both the number of agents and decision-making horizons. My research focuses on developing hierarchical approaches to scale up MARL systems through two complementary directions: structural scaling by increasing the number of coordinated agents and temporal scaling by extending planning horizons. My initial work introduced HiSOMA, a hierarchical framework integrating self-organizing neural networks with MARL for long-horizon planning, and MOSMAC, a benchmark for evaluating MARL methods on multi-objective MARL scenarios. Building on these foundations, my recent work studies L2M2, a novel framework that leverages large language models for high-level planning in hierarchical multi-agent systems. My ongoing research explores complex bimanual control tasks, specifically investigating multi-agent approaches for coordinated dual-hand manipulation.
@inproceedings{geng_hierarchical_2025, series = {{{AAMAS}} '25}, title = {Hierarchical Frameworks for Scaling-up Multi-agent Coordination}, booktitle = {Proceedings of the 24th {{International Conference}} on {{Autonomous Agents}} and {{Multiagent Systems}}}, publisher = {{International Foundation for Autonomous Agents and Multiagent Systems}}, author = {Geng, Minghong}, year = {2025}, month = may, pages = {2932--2934}, isbn = {979-8-4007-1426-9}, address = {Richland, SC, USA}, location = {Detroit, MI, USA}, dimensions = {false}, } - MOSMAC: A Multi-agent Reinforcement Learning Benchmark on Sequential Multi-Objective TasksMinghong Geng, Shubham Pateria, Budhitama Subagdja, and Ah-Hwee TanIn Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, Detroit, MI, USA, May 2025
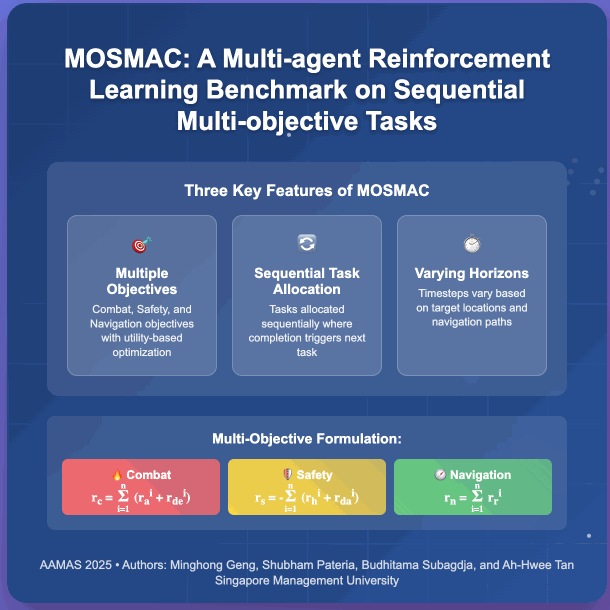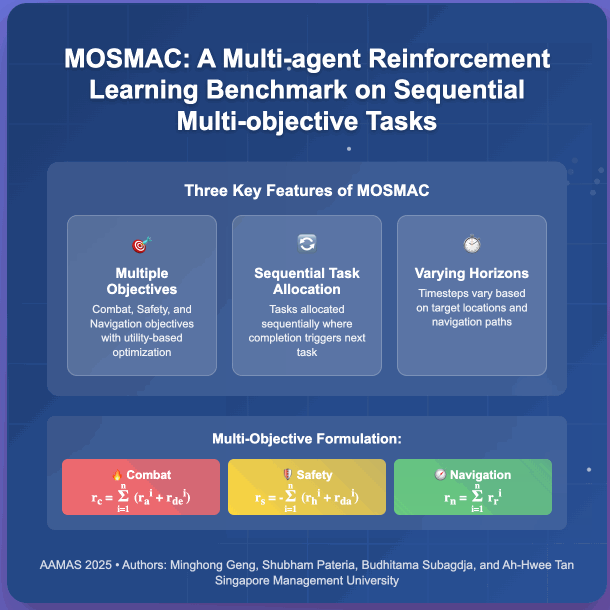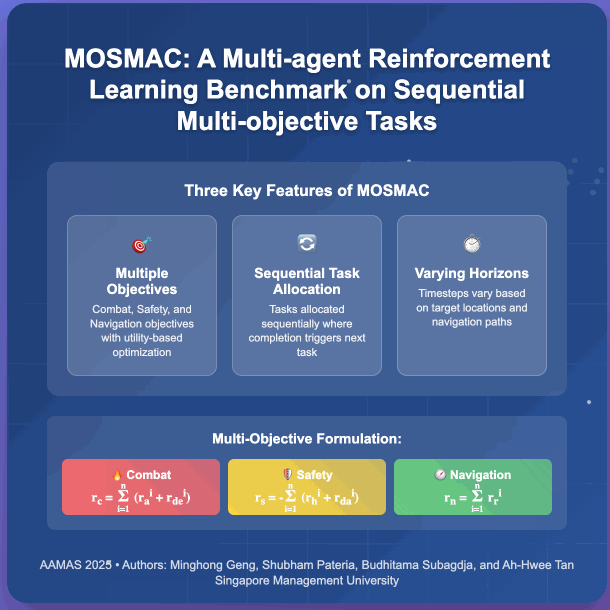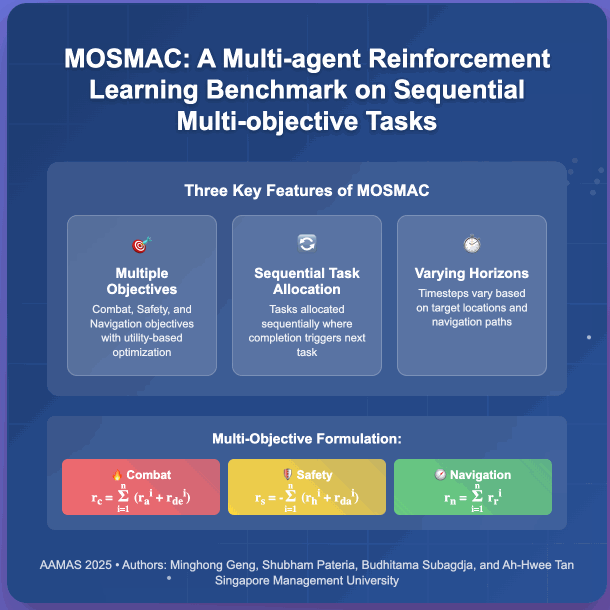
Recent advancements in multi-agent reinforcement learning (MARL) have demonstrated success on various cooperative multi-agent tasks. However, current benchmarks often fall short of representing realistic scenarios that demand agents to execute sequential tasks over long temporal horizons while balancing multiple objectives. To address this limitation, we introduce multi-objective SMAC (MOSMAC), a comprehensive MARL benchmark designed to evaluate MARL methods on tasks involving multiple objectives, sequential subtask assignments, and varying temporal horizons. MOSMAC requires agents to tackle a series of interconnected subtasks in StarCraft II while simultaneously optimizing for multiple objectives, including combat, safety, and navigation. Through rigorous evaluation of nine state-of-the-art MARL algorithms, we demonstrate that MOSMAC presents substantial challenges to existing methods, particularly in long-horizon scenarios. Our analysis establishes MOSMAC as an essential benchmark for bridging the gap between single-objective MARL and multi-objective MARL (MOMARL). The codes for MOSMAC are available at: https://github.com/smu-ncc/mosmac.
@inproceedings{geng_mosmac_2025, series = {{{AAMAS}} '25}, title = {{{MOSMAC}}: {{A Multi-agent Reinforcement Learning Benchmark}} on {{Sequential Multi-Objective Tasks}}}, booktitle = {Proceedings of the 24th {{International Conference}} on {{Autonomous Agents}} and {{Multiagent Systems}}}, publisher = {{International Foundation for Autonomous Agents and Multiagent Systems}}, author = {Geng, Minghong and Pateria, Shubham and Subagdja, Budhitama and Tan, Ah-Hwee}, year = {2025}, month = may, pages = {867--876}, isbn = {979-8-4007-1426-9}, address = {Richland, SC, USA}, location = {Detroit, MI, USA}, dimensions = {false}, }
2024
- HiSOMA: A hierarchical multi-agent model integrating self-organizing neural networks with multi-agent deep reinforcement learningMinghong Geng, Shubham Pateria, Budhitama Subagdja, and Ah-Hwee TanExpert Systems with Applications, Oct 2024
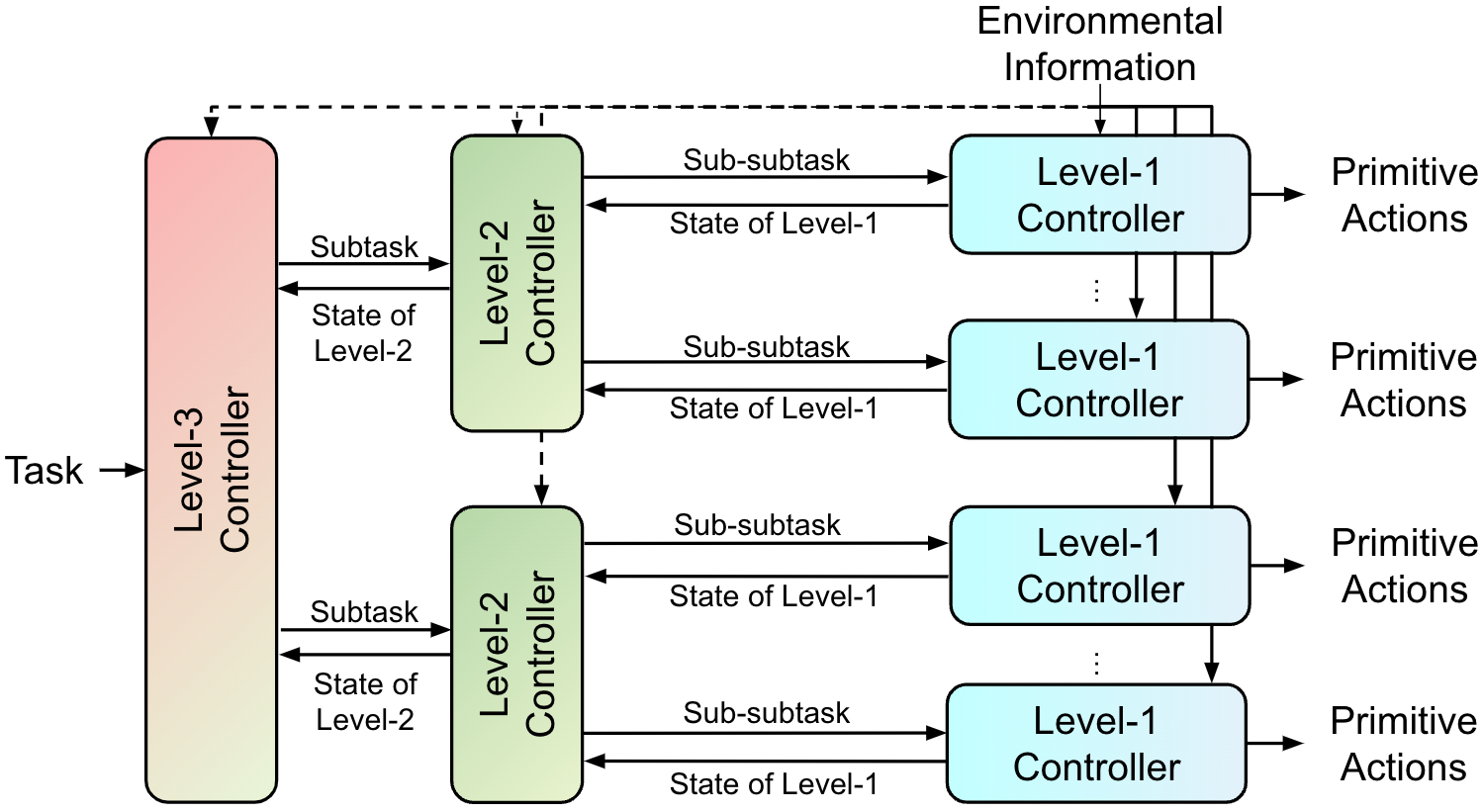
Multi-agent deep reinforcement learning (MADRL) has shown remarkable advancements in the past decade. However, most current MADRL models focus on task-specific short-horizon problems involving a small number of agents, limiting their applicability to long-horizon planning in complex environments. Hierarchical multiagent models offer a promising solution by organizing agents into different levels, effectively addressing tasks with varying planning horizons. However, these models often face constraints related to the number of agents or levels of hierarchies. This paper introduces HiSOMA, a novel hierarchical multi-agent model designed to handle long-horizon, multi-agent, multi-task decision-making problems. The top-level controller, FALCON, is modeled as a class of self-organizing neural networks (SONN), designed to learn high-level decision rules as internal cognitive codes to modulate middle-level controllers in a fast and incremental manner. The middle-level controllers, MADRL models, in turn receive modulatory signals from the higher level and regulate bottom-level controllers, which learn individual action policies generating primitive actions and interacting directly with the environment. Extensive experiments across different levels of the hierarchical model demonstrate HiSOMA’s efficiency in tackling challenging long-horizon problems, surpassing a number of non-hierarchical MADRL approaches. Moreover, its modular design allows for extension into deeper hierarchies and application to more complex tasks with heterogeneous controllers. Demonstration videos and codes can be found on our project web page: https://smu-ncc.github.io.
@article{geng_hisoma_2024, title = {HiSOMA: A hierarchical multi-agent model integrating self-organizing neural networks with multi-agent deep reinforcement learning}, volume = {252}, issn = {0957-4174}, shorttitle = {{HiSOMA}}, url = {https://www.sciencedirect.com/science/article/pii/S0957417424009837}, doi = {10.1016/j.eswa.2024.124117}, journal = {Expert Systems with Applications}, author = {Geng, Minghong and Pateria, Shubham and Subagdja, Budhitama and Tan, Ah-Hwee}, month = oct, year = {2024}, keywords = {Hierarchical control, Multi-agent deep reinforcement learning, Self-Organizing Neural Networks}, pages = {124117}, dimensions = {true}, } - Scaling up Cooperative Multi-agent Reinforcement Learning SystemsMinghong GengIn Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, May 2024
Cooperative multi-agent reinforcement learning methods aim to learn effective collaborative behaviours of multiple agents performing complex tasks. However, existing MARL methods are commonly proposed for fairly small-scale multi-agent benchmark problems, wherein both the number of agents and the length of the time horizons are typically restricted. My initial work investigates hierarchical controls of multi-agent systems, where a unified overarching framework coordinates multiple smaller multi-agent subsystems, tackling complex, long-horizon tasks that involve multiple objectives. Addressing another critical need in the field, my research introduces a comprehensive benchmark for evaluating MARL methods in long-horizon, multi-agent, and multi-objective scenarios. This benchmark aims to fill the current gap in the MARL community for assessing methodologies in more complex and realistic scenarios. My dissertation would focus on proposing and evaluating methods for scaling up multi-agent systems in two aspects: structural-wise increasing the number of reinforcement learning agents and temporal-wise extending the planning horizon and complexity of problem domains that agents are deployed in.
@inproceedings{geng_scaling_2024, series = {{{AAMAS}} '24}, title = {Scaling up Cooperative Multi-agent Reinforcement Learning Systems}, isbn = {9798400704864}, booktitle = {Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems}, publisher = {International Foundation for Autonomous Agents and Multiagent Systems}, author = {Geng, Minghong}, month = may, year = {2024}, pages = {2737--2739}, address = {Richland, SC, USA}, location = {Auckland, New Zealand}, dimensions = {false}, } - Explaining Sequences of Actions in Multi-agent Deep Reinforcement Learning ModelsKhaing Phyo Wai, Minghong Geng, Budhitama Subagdja, Shubham Pateria, and Ah-Hwee TanIn Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, May 2024
This paper introduces a method to explain MADRL agents’ behaviors by abstracting their actions into high-level strategies. Particularly, a spatio-temporal neural network model is applied to encode the agents’ sequences of actions as memory episodes wherein an aggregating memory retrieval can generalize them into a concise abstract representation of collective strategies. To assess the effectiveness of our method, we applied it to explain the actions of QMIX MADRL agents playing a StarCraft Multi-agent Challenge (SMAC) video game. A user study on the perceived explainability of the extracted strategies indicates that our method can provide comprehensible explanations at various levels of granularity.
@inproceedings{wai_explaining_2024, series = {{{AAMAS}} '24}, title = {Explaining Sequences of Actions in Multi-agent Deep Reinforcement Learning Models}, isbn = {9798400704864}, booktitle = {Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems}, publisher = {International Foundation for Autonomous Agents and Multiagent Systems}, author = {Wai, Khaing Phyo and Geng, Minghong and Subagdja, Budhitama and Pateria, Shubham and Tan, Ah-Hwee}, month = may, year = {2024}, pages = {2537--2539}, address = {Richland, SC, USA}, location = {Auckland, New Zealand}, dimensions = {true}, } - Benchmarking MARL on Long Horizon Sequential Multi-Objective TasksMinghong Geng, Shubham Pateria, Budhitama Subagdja, and Ah-Hwee TanIn Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, May 2024
Current MARL benchmarks fall short in simulating realistic scenarios, particularly those involving long action sequences with sequential tasks and multiple conflicting objectives. Addressing this gap, we introduce Multi-Objective SMAC (MOSMAC), a novel MARL benchmark tailored to assess MARL methods on tasks with varying time horizons and multiple objectives. Each MOSMAC task contains one or multiple sequential subtasks. Agents are required to simultaneously balance between two objectives - combat and navigation - to successfully complete each subtask. Our evaluation of nine state-of-the-art MARL algorithms reveals that MOSMAC presents substantial challenges to many state-of-the-art MARL methods and effectively fills a critical gap in existing benchmarks for both single-objective and multi-objective MARL research.
@inproceedings{geng_mosmac_2024, address = {Richland, SC, USA}, series = {{{AAMAS}} '24}, title = {Benchmarking MARL on Long Horizon Sequential Multi-Objective Tasks}, isbn = {9798400704864}, url = {https://dl.acm.org/doi/10.5555/3635637.3663133}, booktitle = {Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems}, publisher = {International Foundation for Autonomous Agents and Multiagent Systems}, author = {Geng, Minghong and Pateria, Shubham and Subagdja, Budhitama and Tan, Ah-Hwee}, month = may, year = {2024}, pages = {2279--2281}, location = {Auckland, New Zealand}, dimensions = {true}, }

.jpg)

2023
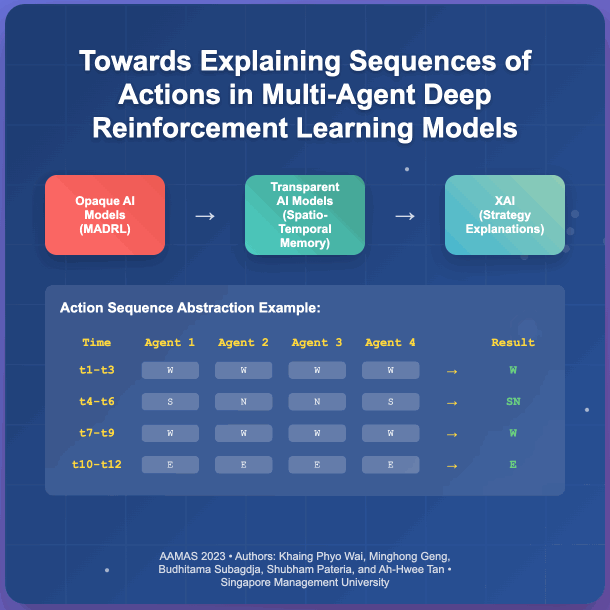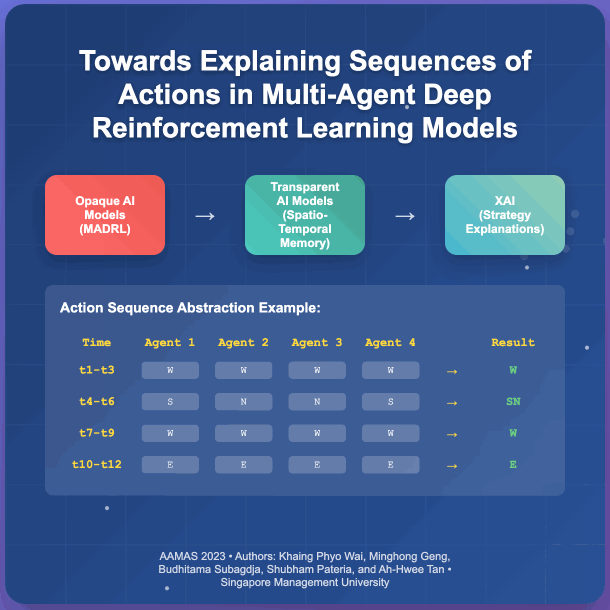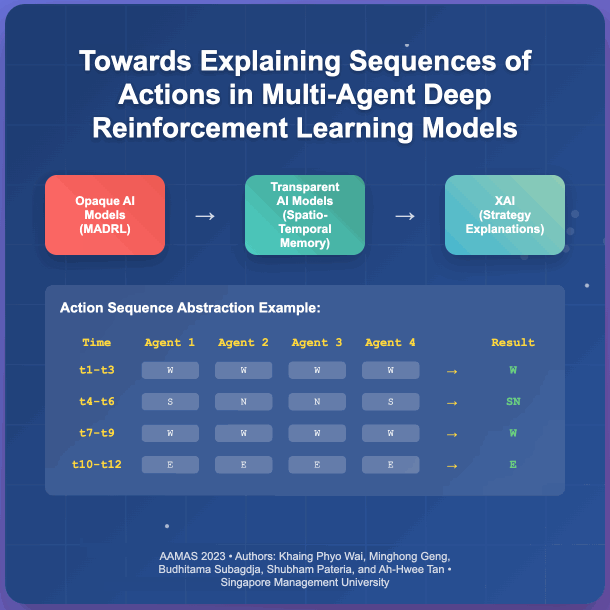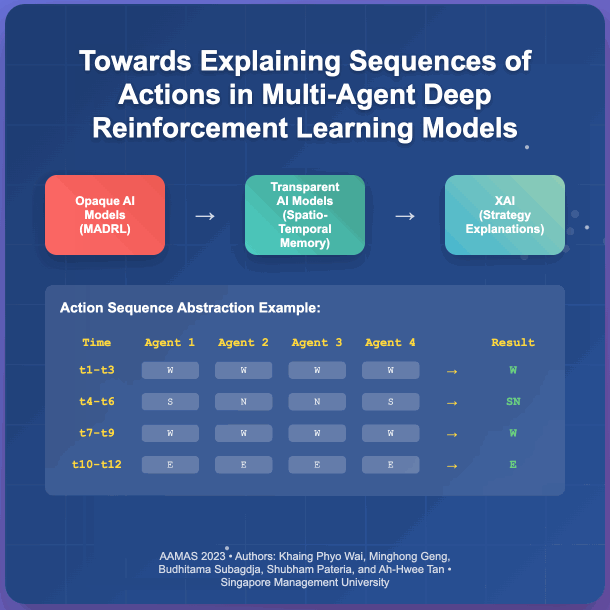
- Towards Explaining Sequences of Actions in Multi-Agent Deep Reinforcement Learning ModelsKhaing Phyo Wai, Minghong Geng, Budhitama Subagdja, Shubham Pateria, and Ah-Hwee TanIn Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, London, UK, May 2023
Although Multi-agent Deep Reinforcement Learning (MADRL) has shown promising results in solving complex real-world problems, the applicability and reliability of MADRL models are often limited by a lack of understanding of their inner workings for explaining the decisions made. To address this issue, this paper proposes a novel method for explaining MADRL by generalizing the sequences of action events performed by agents into high-level abstract strategies using a spatio-temporal neural network model. Specifically, an interval-based memory retrieval procedure is developed to generalize the encoded sequences of action events over time into short sequential patterns. In addition, two abstraction algorithms are introduced, one for abstracting action events across multiple agents and the other for further abstracting the episodes over time into short sequential patterns, which can then be translated into symbolic form for interpretation. We evaluate the proposed method using the StarCraft Multi Agent Challenge (SMAC) benchmark task, which shows that the method is able to derive high-level explanations of MADRL models at various levels of granularity.
@inproceedings{wai_towards_2023, address = {Richland, SC, USA}, series = {{{AAMAS}} '23}, title = {Towards Explaining Sequences of Actions in Multi-Agent Deep Reinforcement Learning Models}, isbn = {978-1-4503-9432-1}, urldate = {2023-09-02}, booktitle = {Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems}, publisher = {International Foundation for Autonomous Agents and Multiagent Systems}, author = {Wai, Khaing Phyo and Geng, Minghong and Subagdja, Budhitama and Pateria, Shubham and Tan, Ah-Hwee}, month = may, year = {2023}, pages = {2325--2327}, location = {London, UK}, dimensions = {true}, }